
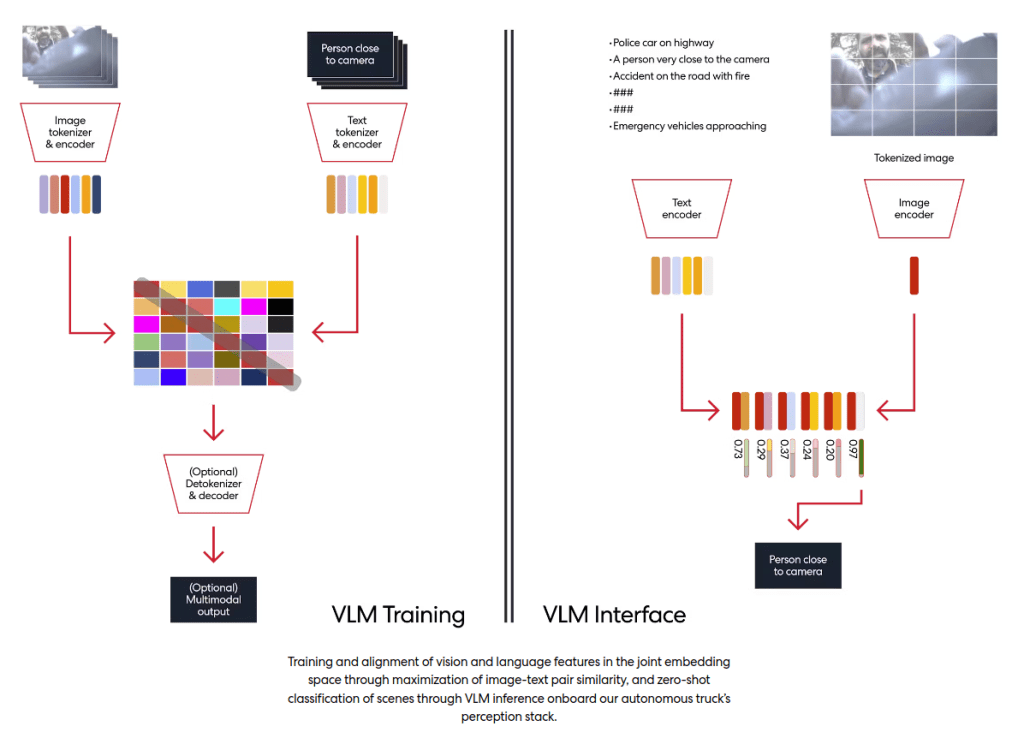
My colleague Shubham Shrivastava posted on Kodiak’s blog about our use of Vision-Language Models. These are deep learning models that build from ChatGPT-like architectures to fuse both visual and textual training data.
Basically, the model can accept as input both images and textual descriptions of those images. This fusion of different types of data generalizes the model to a wider range of inputs. And that generalization helps the model deal with novel inputs that might see on the road.
An illustrative example is that canonical “house on wheels.” Because visual language models “learn” during their training phase that trailers can haul many different things, and because we can use lots of images of houses to also train the model to recognize a house, then the model responds correctly when asked to classify a trailer on the road towing a prefabricated house.
VLMs are at the frontier of AI development, so check out Shubham’s post to learn how we use them!
