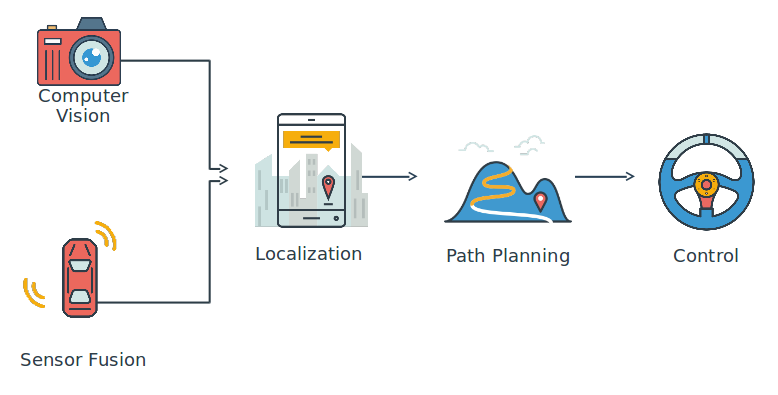
The 8th lesson of the Udacity Self-Driving Car Engineer Nanodegree program is “Convolutional Neural Networks.” This is where students learn to apply deep learning to camera images!
Convolutional neural networks (CNNs) are a special category of deep neural networks that are specifically designed to work with images. CNNs have multiple layers, with each layer connected to the next by “convolutions.”
In practice, what this means is that we slide a patch-like “filter” over the input layer, and the filter applies weights to each artificial neuron in the input layer. The filter connects to a single artificial neuron in the output layer, thereby connecting each neuron in the output layer to a small set of neurons from the input layer.
To make this more concrete, consider this photograph of a dog:

When we run this photograph through a CNN, we’ll slide a filter over the image:

This filter will, broadly speaking, identify basic “features.” It might identify one frame as a curve, and another as a hole:

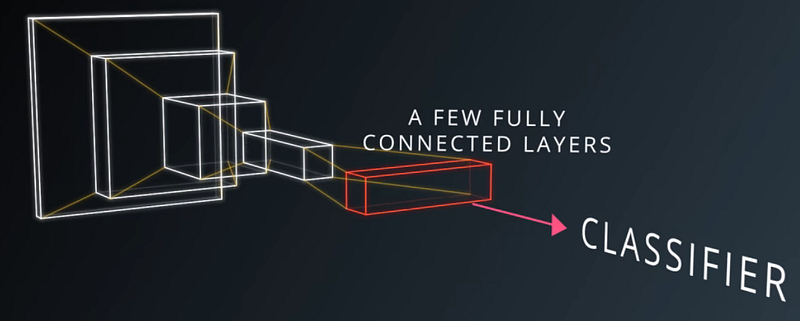
The next layer in the CNN would pass a different filter over a stack of these basic features, and identify more sophisticated features, like a nose:

The final layer of the CNN is responsible for classifying these increasingly sophisticated features as a dog.

This is of course simplified for the sake of explanation, but hopefully it helps to make the process clear.
One of the more vexing aspects of deep learning is that the actual “features” that a network identifies are not necessarily anything humans would think of as a “curve” or a “nose.” The network learns whatever it needs to learn in order to identify the dog most effectively, but that may not be anything humans can really describe well. Nonetheless, this description gets at the broad scope of how a CNN works.
Once students learn about CNNs generally, it’s time to practice building and training them with TensorFlow. As Udacity founder Sebastian Thrun says, “You don’t lose weight by watching other people exercise.” You have to write the code yourself!
The back half of the lesson covers some deep learning topics applicable to CNNs, like dropout and regularization.
The lesson ends with a lab in which students build and train LeNet, the famous network by Yann LeCun, to identify characters. This is a classic exercise for learning convolutional neural networks, and great way to learn the fundamentals.
Ready to start learning how to build self-driving cars yourself? Great! If you have some experience already, you can apply to our Self-Driving Car Engineer Nanodegree program here, and if you’re just getting started, then we encourage you to enroll in our Intro to Self-Driving Cars Nanodegree program here!
~
Thanks to my former colleague, Dhruv Parthasarathy, who built out this intuitive explanation in even greater detail as part of this lesson!
We’re also grateful to Vincent Vanhoucke, Principal Scientist at Google Brain, who teaches the free Udacity Deep Learning course, from which we drew for this lesson.