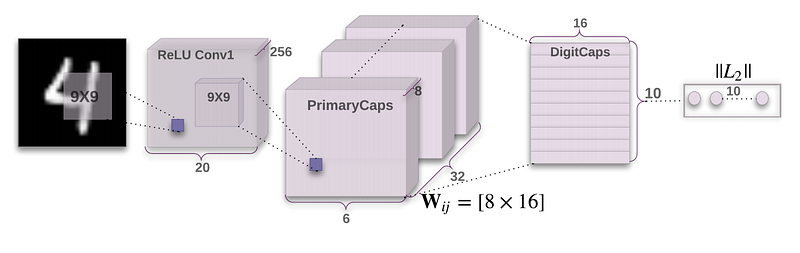
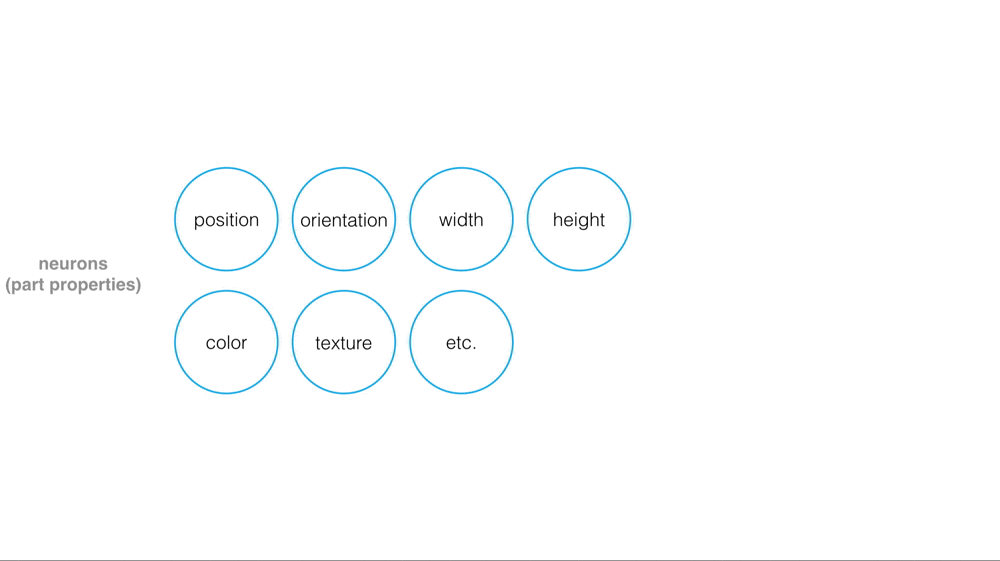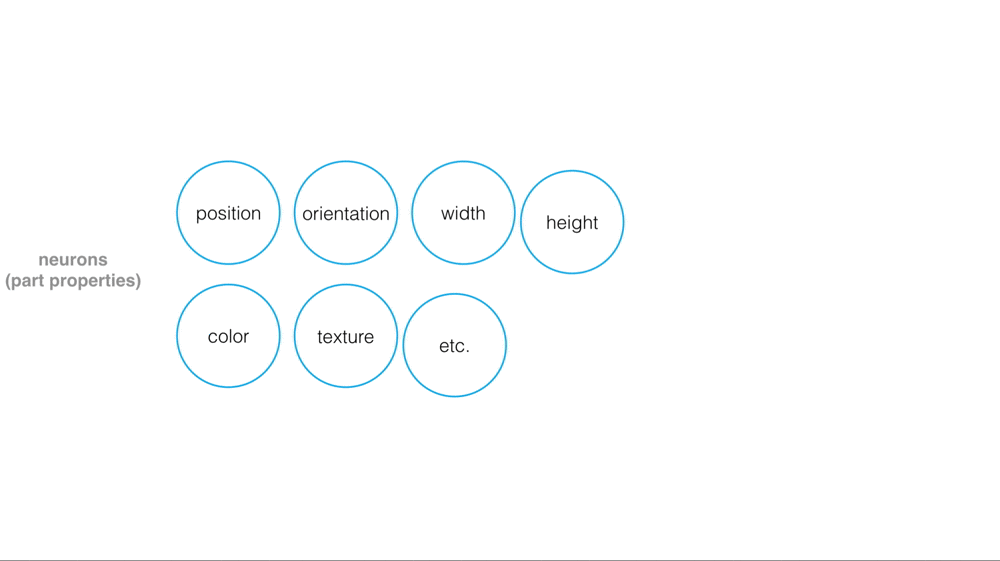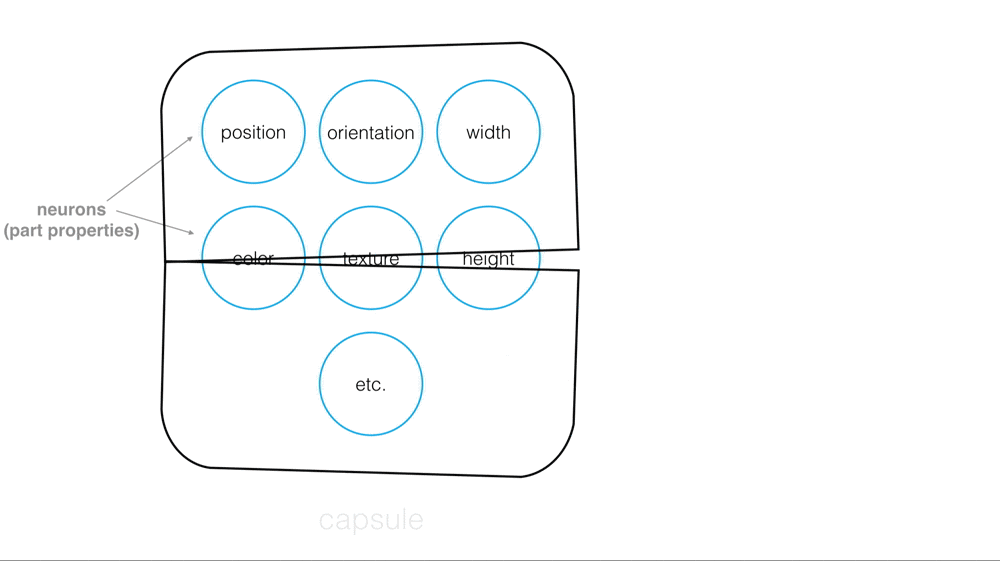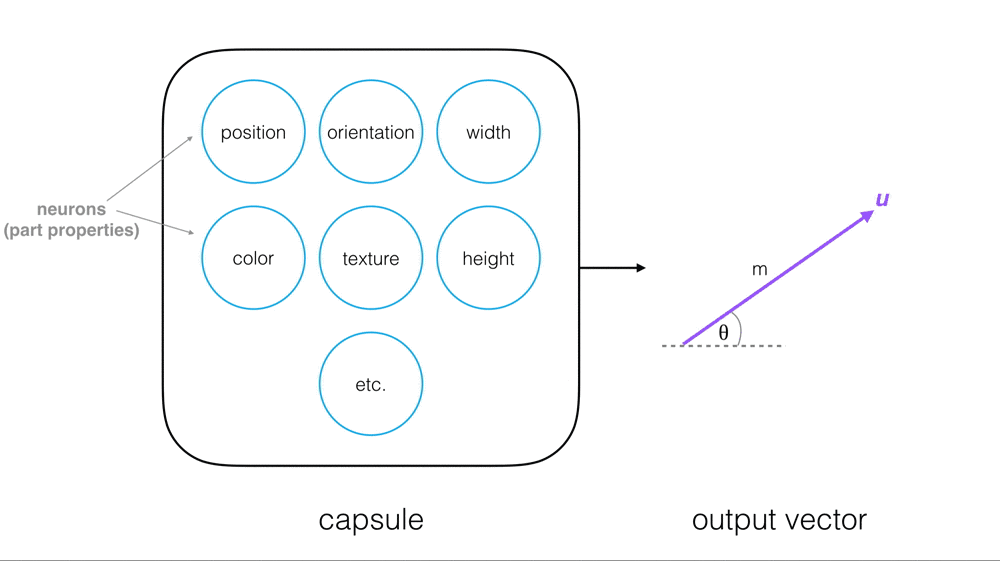
A Waymo blog post caught my eye recently, “VectorNet: Predicting behavior to help the Waymo Driver make better decisions.”
The blog post describes how Waymo uses deep learning to tackle the challenging problem of predicting the future. Specifically, Waymo vehicles need to predict what everyone else on the road is going to do.
As Mercedes-Benz engineers teach in Udacity’s Self-Driving Car Engineer Nanodegree Program, approaches to this problem tend to be either model-based or data-driven.
A model-based approach relies on our knowledge (“model”) of how actors behave. A car turning left through an intersection is likely to continue turning left, rather than come to a complete stop, or reverse, or switch to a right-turn.
A data-driven approach uses machine learning to process data from real world-observations and apply the resulting model to new scenarios.
VectorNet is a data-driven approach takes relies heavily on the semantic information from its high-definition maps. Waymo converts semantic information — turn lanes, stop lines, intersections — into vectors, and then feeds those vectors into a hierarchical graph neural network.
I’m a bit out of touch with the state-of-the-art in deep learning, so I followed a link from Waymo down a rabbit hole. First I read “An Illustrated Guide to Graph Neural Networks,” by a Singaporean undergrad named Rishabh Anand.
That article led me to an hour-long lecture on GNNs by Islem Rekik at Istanbul Technical University.
It was a longer rabbit hole than I anticipated, but this talk was just right for me. It has a quick fifteen minute review of CNNs, followed by a quick fifteen minute review of graph theory. About thirty-minutes in she does a really nice job covering the fundamentals of graph neural networks and how they allow us to feed structured data from a graph into a neural network.
Now that I have a bit of an understanding of GNNs, I’ll need to pop all the way back up to the Waymo blog post and follow it to their academic paper, “VectorNet: Encoding HD Maps and Agent Dynamics from Vectorized Representation.”
The Waymo team is scheduled to present that paper at CVPR 2020 next month.