
I have a pretty awesome backlog of blog posts from Udacity Self-Driving Car students, partly because they’re doing awesome things and partly because I fell behind on reviewing them for a bit.
Here are five that look pretty neat.
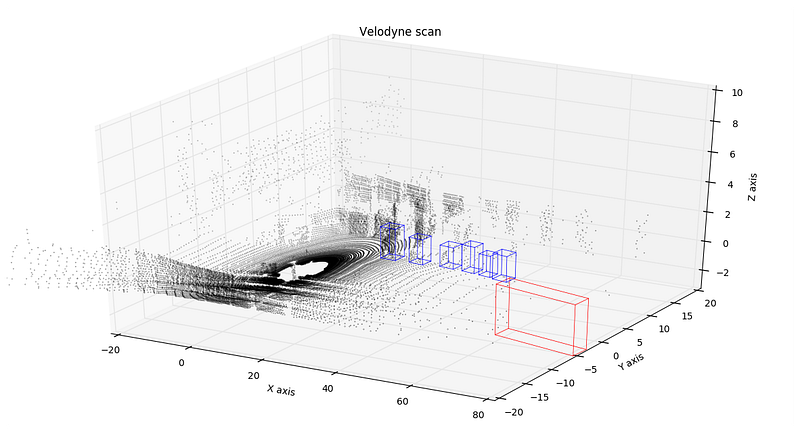
Visualizing lidar data

Alex visualizes lidar data from the canonical KITTI dataset with just a few simple Python commands. This is a great blog post if you’re looking to get started with point cloud files.
“A lidar operates by streaming a laser beam at high frequencies, generating a 3D point cloud as an output in realtime. We are going to use a couple of dependencies to work with the point cloud presented in the KITTI dataset: apart from the familiar toolset of
numpyandmatplotlibwe will usepykitti. In order to make tracklets parsing math easier we will use a couple of methods originally implemented by Christian Herdtweck that I have updated for Python 3, you can find them insource/parseTrackletXML.pyin the project repo.”
TensorFlow with GPU on your Mac
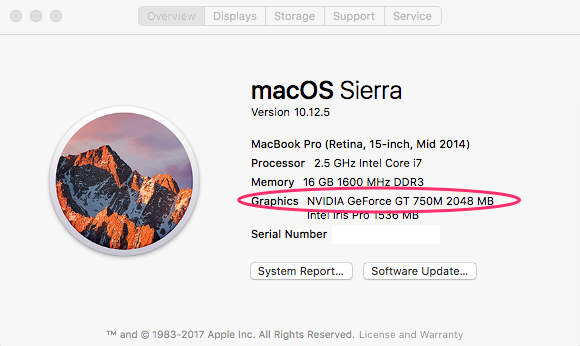
The most popular laptop among Silicon Valley software developers is the Macbook Pro. The current version of the Macbook Pro, however, does not include an NVIDIA GPU, which restricts its ability to use CUDA and cuDNN, NVIDIA’s tools for accelerating deep learning. However, older Macbook Pro machines do have NVIDIA GPUs. Darien’s tutorial shows you how to take advantage of this, if you do have an older Macbook Pro.
“Nevertheless, I could see great improvements on performance by using GPUs in my experiments. It worth trying to have it done locally if you have the hardware already. This article will describe the process of setting up CUDA and TensorFlow with GPU support on a Conda environment. It doesn’t mean this is the only way to do it, but I just want to let it rest somewhere I could find it if I needed in the future, and also share it to help anybody else with the same objective. And the journey begins!”
(Part 1) Generating Anchor boxes for Yolo-like network for vehicle detection using KITTI dataset.

Vivek is constantly posting super-cool things he’s done with deep neural networks. In this post, he applies YOLOv2 to the KITTI dataset. He does a really nice job going through the process of how he prepares the data and selects his parameters, too.
“In this post, I covered the concept of generating candidate anchor boxes from bounding box data, and then assigning them to the ground truth boxes. The anchor boxes or templates are computed using K-means clustering with intersection over union (IOU) as the distance measure. The anchors thus computed do not ignore smaller boxes, and ensure that the resulting anchors ensure high IOU between ground truth boxes. In generating the target for training, these anchor boxes are assigned or are responsible for predicting one ground truth bounding box. The anchor box that gives highest IOU with the ground truth data when located at its center is responsible for predicting that ground truth label. The location of the anchor box is the center of the grid cell within which the ground truth box falls.”
Building a Bayesian deep learning classifier

This post is kind of a tour de force in investigating the links between probability, deep learning, and epistemology. Kyle is basically replicating and summarizing the work of Cambridge researchers who are trying to merge Bayesian probability with deep learning learning. It’s long, and it will take a few passes through to grasp everything here, but I am interested in Kyle’s assertion that this is a path to merge deep learning and Kalman filters.
“Self driving cars use a powerful technique called Kalman filters to track objects. Kalman filters combine a series of measurement data containing statistical noise and produce estimates that tend to be more accurate than any single measurement. Traditional deep learning models are not able to contribute to Kalman filters because they only predict an outcome and do not include an uncertainty term. In theory, Bayesian deep learning models could contribute to Kalman filter tracking.”
Build your own self driving (toy) car

Bogdon started off with the now-standard Donkey Car instructions, and actually got ROS running!
“I decided to go for Robotic Operating System (ROS) for the setup as middle-ware between Deep learning based auto-pilot and hardware. It was a steep learning curve, but it totally paid off in the end in terms of size of the complete code base for the project.”
