

Recently, Apple made what they must have known would be a big splash by silently publishing a research paper with results from a deep neural network that two of their researchers built.
The network and the paper in question were clearly designed for autonomous driving, which Apple has been working on, more or less in secret, for years.
The network in question — VoxelNet — has been trained to perform object detection on lidar point clouds. This isn’t a huge leap from object detection on images, which has been a topic of deep learning research for several years, but it is a new frontier in deep learning for autonomous vehicles. Kudos to Apple for publishing their results.
VoxelNet (by Apple), draws heavily on two previous efforts at applying deep learning to lidar point clouds, both by Baidu-affiliated researchers. Since the three papers kind of work as a trio, I did a quick scan of them together.
3D Fully Convolutional Network for Vehicle Detection in Point Cloud
Bo Li (Baidu)
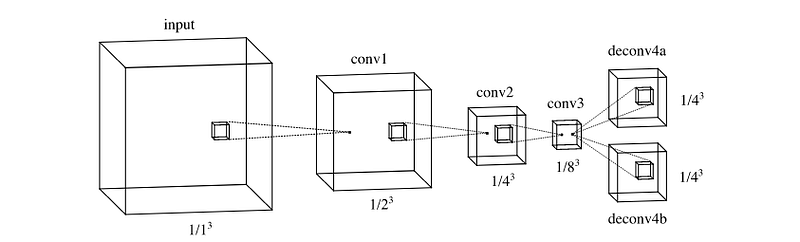
Bo Li basically applies the DenseBox fully convolutional network (FCN) architecture to a three-dimensional point cloud.
To do this, Li:
- Divides the point cloud into voxels. So instead of running 2D pixels through a network, we’re running 3D voxels.
- Trains an FCN to identify features in the voxel-ized point cloud.
- Upsamples the FCN to produce two output tensors: an objectness tensor, and a bounding box tensor.
- The bounding box tensor is probably more interesting for perception purposes. It draws a bounding box around cars on the road.
- Q.E.D.
Multi-View 3D Object Detection Network for Autonomous Driving
Xiaozhi Chen, Huimin Ma, Ji Wan, Bo Li, Tian Xia (Tsinghua and Baidu)
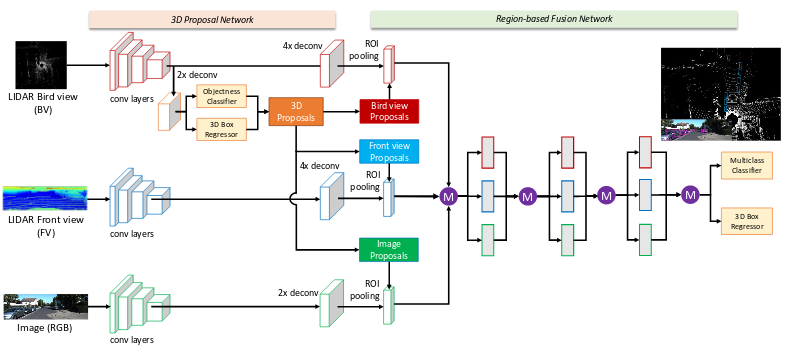
A team of Tsinghua and Baidu researchers developed Multi-View 3D (MV3D) networks, which combine lidar and camera images in a complex neural network pipeline.
In contrast to Li’s solo work, which constructs voxels out of the lidar point cloud, MV3D simply takes two separate 2D views of the point cloud: one from the front and one from the top (birds’ eye). MV3D also uses the 2D camera image associated with each lidar scan.
That provides three separate 2D images (lidar front view, lidar top view, camera front view).
MV3D uses each view to create a bounding box in two-dimensions. Birds-eye view lidar created a bounding box parallel to the ground, whereas front-view lidar and camera view each create a 2D bounding box perpendicular to the ground. Combining these 2D bounding boxes creates a 3D bounding box to draw around the vehicle.
At the end of the network, MV3D employs something called “deep fusion” to combine output from each of the three neural network pipelines (one associated with each view). I’ll be honest — I don’t really understand how “deep fusion” works, so leave me a note in the comments if you can follow what they’re doing.
The results are a classification of the object and a bounding box around it.
VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection
Yin Zhou, Oncel Tuzel (Apple)
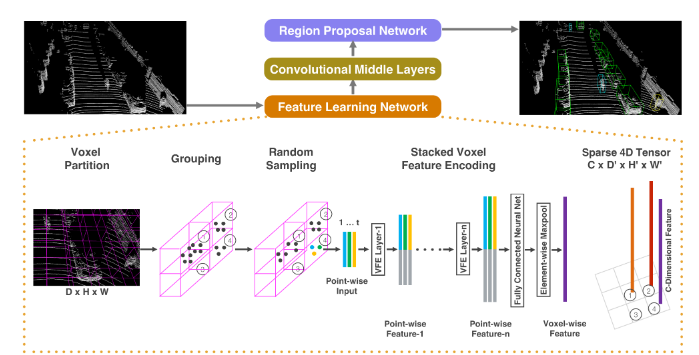
That brings us to VoxelNet, from Apple, which got so much press recently.
VoxelNet has three components, in order:
- Feature Learning Network
- Convolutional Middle Layers
- Region Proposal Network
The Feature Learning Network seems to be the main “contribution to knowledge”, as the scholars say.
It seems that what this network does is start with a semi-random sample of points from within “interesting” (my word, not theirs) voxels. This sample of points gets run through a fully-connected (not fully-convolutional) network. This network learns point-wise features which are relevant to the voxel from which the points came.
The network, in fact, uses these point-wise features to develop voxel-wise features that describe each of the “interesting” voxels. I’m oversimplifying wildly, but think of this as learning features that describe each voxel and are relevant to classifying the part of the vehicle that is in that voxel. So a voxel might have features like “black”, “rubber”, and “treads”, and so you could guess that the voxel captures part of a tire. Of course, the real features won’t necessarily be intelligible by humans, but that’s the idea.
These voxel-wise features can then get pumped through the Convolutional Middle Layers and finally through the Region Proposal Network and, voila, out come bounding boxes and classifications.
One of the most impressive parts of this line of research is just how new it is. The two Baidu papers were both first published online a year ago, and only made it into conferences in the last six months. The Apple paper only just appeared online in the last couple of weeks.
It’s an exciting time to be building deep neural networks for autonomous vehicles.
