

Lyft Level 5 recently published an amazing overview of their PyTorch-based machine learning pipeline.
They confess that a few years ago, their development process was slow:
“Our first production models were taking days to train due to increases in data and model sizes.…Our initial deployment process was complex and model developers had to jump through many hoops to turn a trained model into a “AV-ready” deployable model….We saw from low GPU and CPU utilization that our initial training framework wasn’t able to completely utilize the hardware.”
The post proceeds to described the new pipeline Lyft built to overcome these obstacles. They started with a proof-of-concept for lidar point cloud segmentation, and then grew that into a production system.
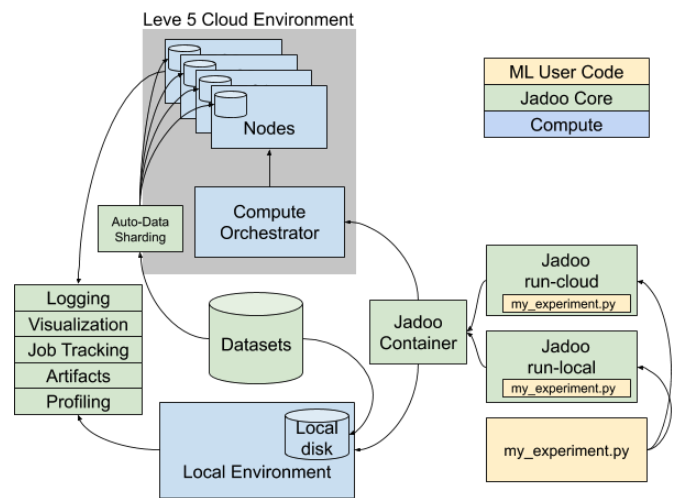
The pipeline accomplishes a lot of infrastructure wins.
Testing. The pipeline incorporates continuous integration testing, both to ensure that the models don’t regress, and also to verify that the code researchers write will run in the PyTorch-based vehicle environment.
Containerization. Lyft invested in a uniform container environment, to mitigate the distinction between local and cloud model training.
Deployment. The system relies heavily on LibTorch and TorchScript for deployment to the vehicle’s C++ runtime. Depending on existing libraries reduces the amount of custom code Lyft’s team needs to write.
Distributed Training. PyTorch provides a fair bit of built-in support for distributed training across GPU clusters.
There’s a lot more in the post. It’s a pretty rare glimpse of a machine learning team’s internal infrastructure, so check it out!
