I interviewed Ben Alfi, the CEO of Blue White Robotics, and wrote for Forbes.comabout the company’s aspirations to provide a vendor-neutral cloud robotics platform.
The company aspires to support any type of robot on its platform. The management and orchestration that Blue White Robotics aims to provide its customers is reminiscent of the functionality that cloud computing providers, such as Amazon Web Services or Microsoft Azure, offer. Just as cloud computing services typically don’t build servers themselves, but rather rent them to customers on-demand, Blue White Robotics hopes to achieve the same with autonomous vehicles.
This expands on my post about the company from a few weeks ago. After writing about them a little bit here, I was intrigued and was fortunate to be able to talk with their executive leadership for a deeper dive. I enjoyed it and I hope you do, too!
The US Army spent about a month this summer testing self-driving combat vehicles, and is pretty bullish on the results. Major Cory Wallace, one of the test leaders, concluded:
“There’s no reason why we are using humans to breach complex obstacles while under fire. We have the technology to be better. The technology on our cars is often better than what we have on some of the combat platforms today. I am very excited to see that paradigm shift.”
The write-ups I’ve seen on this testing focus on the harm-reduction aspects of the technology, as does Major Wallace. Nonetheless, I would imagine there are potential performance enhancements the military might gain by automating fighting vehicles.
The analogy that jumps out at me is agriculture, where the real benefit of autonomous tractors and other farm equipment comes from precision, which leads to increased crop yields. The benefit from labor reduction is less important in that context.
In the short-run, I can certainly see why the military might use robots instead of humans for tasks like bomb disposal or scouting, even if the performance is inferior. Better to risk an automated tank that a platoon.
But in the long run I would imagine these vehicles will outperform manual drivers and gunners. That increased performance could cut two ways simultaneously: on the one hand, precision would hopefully mean less collateral damage and fewer civilian casualties; on the other hand, the Terminator 2 scenario comes to mind.
Update
My former colleague Art Gillespie, who is was a US Army soldier and is now an autonomous vehicle engineer, provides insightful commentary:
My take on this is that effective autonomy on the battlefield won’t be 1:1 analogous with current platforms’ form factors. Do you even need tanks if you can swarm a target with hundreds or even thousands of disposable smaller robots with similar payloads?
Every month Robotics Business Review compiles a list of private financing deals for robotics companies.
In April, as the world shut down for COVID-19, funding basically dried up.
“Robotics Business Reviewtracked about 26 transactions worth a total of more than $600 million last month, compared with 29 deals worth $2.7 billion in March 2020 and 30 transactions worth $6.5 billion in April 2019.”
Many of the April transactions that did occur were in China.
May, however, showed a meaningful uptick. May 2020 numbers were comparable to where they were a year ago, and at least in the same order of magnitude as the March 2020 figures.
The May figures were led by huge funding rounds for Waymo and Didi. The rest of the May transactions totaled only $250 million.
For comparison, the May 2019 figures were even more concentrated, with the bulk of the month’s investments driven by a huge fundraising round for Cruise Automation.
I’m not quite ready to declare a return to normalcy yet, but it’s a big step in the right direction.
I’ve been thumbing through Sebastian’s magnum opus, Probabilistic Robotics. The book is now13 years old, but it remains a great resource for roboticists. Kind of funny to think that, when Sebastian wrote this, he hadn’t even started to work on self-driving cars yet!
The chapter on Markov decision processes (MDPs) covers how to make robotic planning decisions under uncertainty. One of the key assumptions of MDPs is that the agent (robot) can observe its environment perfectly. This turns out to be an unrealistic assumption, which leads to further types of planning algorithms, principally partially observable Markov decision processes (POMDPs).
Nonetheless, ordinary Markov decision processes are a helpful place to start when thinking about motion planning.
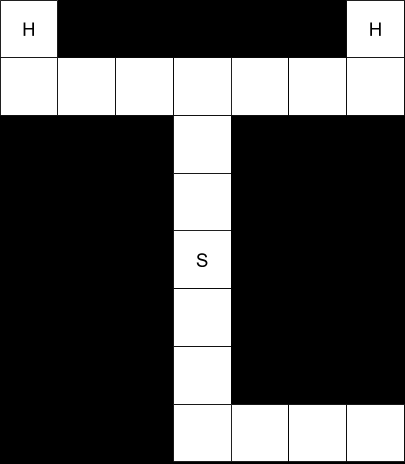
“In this exercise, you are asked to extend dynamic programming to an environment with a single hidden state variable. The environment is a maze with a designated start marked “S”, and two possible goal states, both marked “H”.
“What the agent does not know is which of the two goal states provides a positive reward. One will give +100, whereas the other will give -100. There is a .5 probability that either of those situations is true. The cost of moving is -1; the agent can only move into the four directions north, south, east, and west. Once a state labeled “H” has been reached, the play is over.”
So far, so good.
“(a) Implement a value iteration algorithm for this scenario. Have your implementation compute the value of the starting state. What is the optimal policy?”
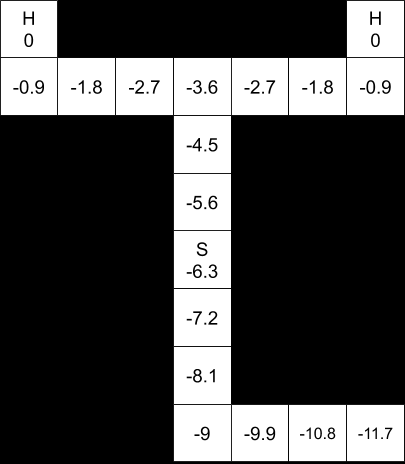
The optimal policy here depends on whether we assume the agent must move. If the agent is allowed to remain stationary, then the value of the starting state is 0, because the optimal policy is to stay put.
Calculating the expected reward from reaching state “H” is straightforward. The expected reward is 0, because there’s a 50% chance of a +100 reward, but also a 50% chance of a -100 reward.
0.5 * (+100) + 0.5 * (-100) = 50 + (-50) = 0
Once we establish that, the optimal policy is intuitive. There is no positive reward for reaching any state, but there is a cost to moving to any state. Don’t incur a cost if there’s no possible reward.
The optimal policy changes, however, if the rules state that we must move. In that case, we want to end the game as quickly as possible.
Under this set of rules, the value function decreases as we approach either “H”. The intuition is that the game has no benefits, only costs, so we want to end the game as quickly as possible. From a policy perspective, we want to follow the gradient toward higher values, so if we start at “S”, we wind up trending toward “H”.
“(b) Modify your value algorithm to accommodate a probabilistic motion model: with 0.9 chance the agent moves as desired; with 0.1 chance it will select any of the other three directions at random. Run your value iteration algorithm again, and compute both the value of the starting state, and the optimal policy.”
Once again, the optimal policy depends on whether we can remain stationary. If we can remain stationary, then the value of all cells is 0, and the optimal policy is to stay put. The uncertainty in motion that has just been introduced does not affect the policy, because there’s still no reward for moving anywhere.
If, however, we are required to move, calculating the policy becomes more complex. At this point we really need a computer to calculate the value function, because we have to iterate over all the cells on the map until values converge. For each cell, we have to look at each action and sum the 90% probability that the action will execute properly, and the 10% probability that the action will misfire randomly. Then we pick the highest-value action. Once we do this for every cell, we repeat the cycle over all the cells again, and we keep doing this until the values stabilize.
The first pass in the iteration sets all cells to 0. Depending on which direction we iterate from, the next step might look like this:
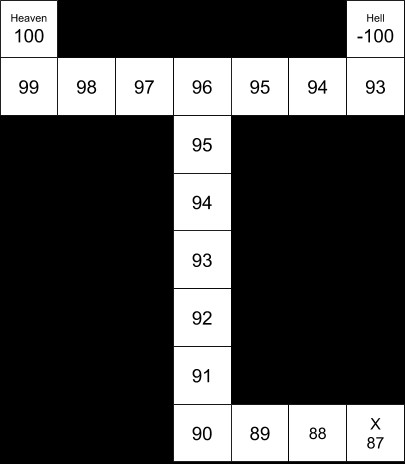
Nonetheless, even without a computer, it seems pretty clear that the optimal policy is still for our agent to stay put in the start cell. Without any information about which “H” is heaven and which is hell, there’s no ultimate reward for going anywhere.
“(c) Now suppose the location labeled X contains a sign that informs the agent of the correct assignment of rewards to the two states labeled “H”. How does this affect optimal policy?”
Without computing the policy, it seems likely that the optimal policy will involve going to the sign, identifying heaven and hell on the map, and then proceeding to heaven.
This policy seems qualitatively clear because of the relatively high payoff for reaching heaven (+100), the relatively low cost of motion (-1), the relatively high probability of the motion executing accurately (0.9), and the relatively small size of the map (distance from S to X to H = 19).
It’s easy to imagine tweaking these parameters such that it’s no longer so obvious that it makes sense to go find the sign. With different parameters, it might still make sense to stay put at S.
“(d) How can you modify your value iteration algorithm to find the optimal policy? Be concise. State any modifications to the space over which the value function is defined.”
Basically, we need to figure out the value of reaching the sign. There are essentially two value functions: the value function when we cannot observe the state, and the value function when we can.
Another way to put this is that going to the sign is like taking a measurement with a sensor. We have prior beliefs about the state of the world before we reach the sign, and then posterior beliefs once we get the information from the sign. Once we transition from prior to posterior beliefs, we will need to recalculate our value function.
An important point here is that this game assumes the sign is 100% certain, which makes the model fully observable. That’s not the case with normal sensors, which is why real robots have to deal with partially observable Markov decision processes (POMDPs).
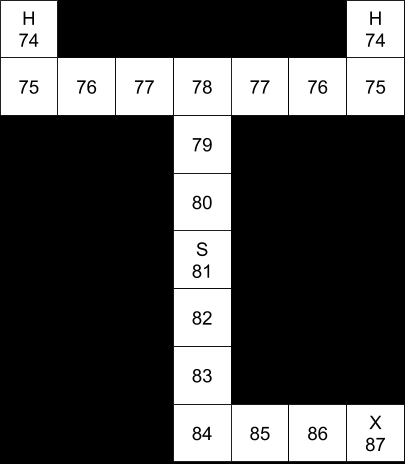
“(e) Implement your modification, and compute both the value of the starting state and the optimal policy.”
Again, we’d need to write code to actually implement this, but the general idea is to have two value functions. The value of X will be dependent on the posterior value function (the value function that we can calculate once we know which is heaven and which is hell). Then we use that value of X to calculate our prior distribution.
For example, here are the value functions, assuming perfect motion:
The posterior value function, after reading the sign at “X”.The prior value function, before reading the sign at “X”.
I am super excited that today Udacity launched the C++ Nanodegree Program! My team and I have been building this for the last several months and we can’t wait to share it with students. 💻
There are so many jobs available for C++ engineers. 😄
One of my favorite parts of building this program was the opportunity to talk with C++ creator Bjarne Stroustrup. Bjarne cares a lot about teaching C++ well, and he was incredibly generous with his time and advice on the curriculum. He also graciously sat for many videos that appear in the program, in which he explains how different features of the language work, why those features came about, and the right way to use them.
The Nanodegree Program is composed of five courses, each lasting one month:
Foundations: Learn the basics of “modern” C++ (C++17!) syntax and operators. You’ll finish this course by building a real-world route planner using OpenStreetMap data!
Object-Oriented Programming: Design programs using object-oriented C++ features, including classes and templates. The final project for this course is to implement an htop-like process manager for Linux (we provide a full Linux desktop through your browser!).
Memory Management: Grasp the power of C++ by learning how to manage resources on the stack and the free store. In particular, learn how to leverage Resource Acquisition Is Initialization (RAII) principles to scope your resources and handle them automatically!
Concurrency: Parallel processing has been a key driver of the adoption of C++ into real-time and embedded systems, like self-driving cars. In this course, you’ll exploit parallel processing to accelerate your programs, starting with parallel implementations of standard library algorithms and moving all the way to thread synchronization and communication.
C++ is such an important skill, and I think this course teaches “modern” C++ in a really intuitive and hands-on way, just like all Udacity courses.
Check out the Nanodegree Program and enroll today!
This Thursday, August 23rd, at 9am Pacific Time, I will be hosting an online open house for Udacity’s School of Autonomous Systems. RSVP now to join me, my Udacity colleagues, our alumni, and other potential students, and learn about our many exciting programs!
At the Open House, I’ll share an overview of each program, compare them, and describe the careers for which each option prepares you.
We’ll finish with a live question-and-answer session, co-hosted by myself and several of my Udacity instructional colleagues, to answer as many of your questions as we can.
RSVP now to join us on Thursday! And don’t worry if you can’t make it! RSVP via the link, and we’ll send you the recording of the open house so you don’t miss out!
Mithi published a three-part series about what she calls “the most difficult project yet” of the Nanodegree Program. In Part 1, she outlines the goals and constraints of the project, and decides on how to approach the solution. Part 2 covers the architecture of the solution, including the classes Mithi developed and the math for trajectory generation. Part 3 covers implementation, behavior planning, cost functions, and some extra considerations that could be added to improve the planner. This is a great series to review if you’re just starting the project.
“I decided that I should start with a simple model with many simple assumptions and work from there. If the assumption does not work then I will then make my model more complex. I should keep it simple (stupid!).
A programmer should not add functionality until deemed necessary. Always implement things when you actually need them, never when you just foresee that you need them. A famous programmer said that somewhere.
My design principle is, make everything simple if you can get away with it.”
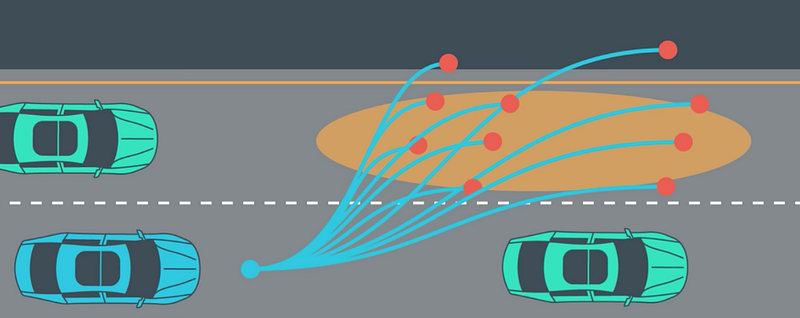
Mohan takes a different approach to path planning, in which he combines a cost function with a feasibility checklist. He builds a cost function and then ranks each lane by how it does on a cost function. Then he decides whether to move to a lane based on the feasibility checklist.
“This comes down to two things (and I’m going to be specific to highway scenario).
Estimating a score for each lane, to determine the best lane for us to be in (efficiency)
Evaluating the feasibility of moving to that lane in the immediate future (safety & comfort)”
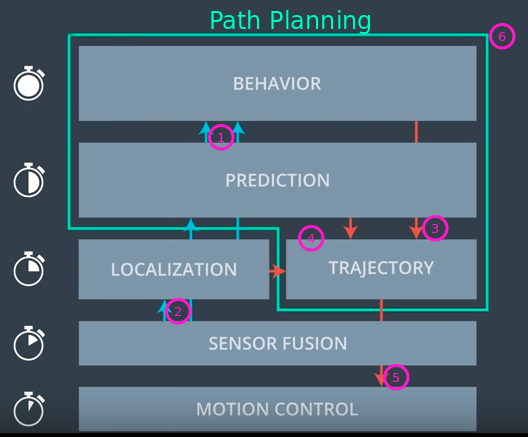
The 11th post in Andrew’s series on the Nanodegree Program covers Term 3 broadly and path planning specifically. In particular, Andrew lays out where this path planning project falls in the taxonomy of autonomous driving, and the high-level inputs and outputs of a path planner. This is a great post to review if you’re interested in what a path planner does.
“I found the path planning project challenging, in large part due to fact that we are implementing SAE Level 4 functionality in C++ and the complexity that comes with the interactions required between the various modules.”
These examples make clear the vision, skill, and tenacity our students are applying to even the most difficult challenges, and it’s a real pleasure to share their incredible work. It won’t be long before these talented individuals graduate the program, and begin making significant, real-world contributions to the future of self-driving cars. I know I speak for everyone at Udacity when I say that I’m very excited for the future they’re going to help build!
The focus of Term 1 was applying machine learning to automotive tasks: deep learning, convolutional neural networks, support vector machines, and computer vision.
In Term 2, students will build the core robotic functions of an autonomous vehicle system: sensor fusion, localization, and control. This is the muscle of a self-driving car!
Term 2
Sensor Fusion
Our terms are broken out into modules, which are in turn comprised of a series of focused lessons. This Sensor Fusion module is built with our partners at Mercedes-Benz. The team at Mercedes-Benz is amazing. They are world-class automotive engineers applying autonomous vehicle techniques to some of the finest vehicles in the world. They are also Udacity hiring partners, which means the curriculum we’re developing together is expressly designed to nurture and advance the kind of talent they would like to hire!
Lidar Point Cloud
Below please find descriptions of each of the lessons that together comprise our Sensor Fusion module:
Sensors The first lesson of the Sensor Fusion Module covers the physics of two of the most import sensors on an autonomous vehicle — radar and lidar.
Kalman Filters Kalman filters are the key mathematical tool for fusing together data. Implement these filters in Python to combine measurements from a single sensor over time.
C++ Primer Review the key C++ concepts for implementing the Term 2 projects.
Project: Extended Kalman Filters in C++ Extended Kalman filters are used by autonomous vehicle engineers to combine measurements from multiple sensors into a non-linear model. Building an EKF is an impressive skill to show an employer.
Unscented Kalman Filter The Unscented Kalman filter is a mathematically-sophisticated approach for combining sensor data. The UKF performs better than the EKF in many situations. This is the type of project sensor fusion engineers have to build for real self-driving cars.
Project: Pedestrian Tracking Fuse noisy lidar and radar data together to track a pedestrian.
Localization
This module is also built with our partners at Mercedes-Benz, who employ cutting-edge localization techniques in their own autonomous vehicles. Together we show students how to implement and use foundational algorithms that every localization engineer needs to know.
Particle Filter
Here are the lessons in our Localization module:
Motion Study how motion and probability affect your belief about where you are in the world.
Markov Localization Use a Bayesian filter to localize the vehicle in a simplified environment.
Egomotion Learn basic models for vehicle movements, including the bicycle model. Estimate the position of the car over time given different sensor data.
Particle Filter Use a probabilistic sampling technique known as a particle filter to localize the vehicle in a complex environment.
High-Performance Particle Filter Implement a particle filter in C++.
Project: Kidnapped Vehicle Implement a particle filter to take real-world data and localize a lost vehicle.
Control
This module is built with our partners at Uber Advanced Technologies Group. Uber is one of the fastest-moving companies in the autonomous vehicle space. They are already testing their self-driving cars in multiple locations in the US, and they’re excited to introduce students to the core control algorithms that autonomous vehicles use. Uber ATG is also a Udacity hiring partner, so pay attention to their lessons if you want to work there!
Here are the lessons:
Control Learn how control systems actuate a vehicle to move it on a path.
PID Control Implement the classic closed-loop controller — a proportional-integral-derivative control system.
Linear Quadratic Regulator Implement a more sophisticated control algorithm for stabilizing the vehicle in a noisy environment.
Project: Lane-Keeping Implement a controller to keep a simulated vehicle in its lane. For an extra challenge, use computer vision techniques to identify the lane lines and estimate the cross-track error.
I hope this gives you a good sense of what students can expect from Term 2! Things may change along the way of course, as we absorb feedback, incorporate new content, and take advantage of new opportunities that arise, but we’re really excited about the curriculum we’ve developed with our partners, and we can’t wait to see what our students build!
In case you’d like a refresher on what was covered in Term 1, you can read my Term 1 curriculum post here.
In closing, if you haven’t yet applied to join the Udacity Self-Driving Car Engineer Nanodegree Program, please do! We are taking applications for the 2017 terms and would love to have you in the class!
The online course I’ve been working on most rigorously of late [although I’m still one week behind 😦 ], is Control of Mobile Robots.
The course is offered via Coursera, and taught by Magnus Egerstedt and his team at Georgia Tech.
I really like this course!
It offers a great introduction to control theory, and hits the right blend of mathematics and applications for me.
We just finished the distinction and relationship between controllability and observability. These are good introductory concepts and they were conveyed at an introductory level, which I think will provide a solid foundation for more advanced courses.
I’ve written previously of my love for Udacity, which has found a great formula for teaching technical courses on its own platform. Coursera has different strengths and weaknesses, and Control of Mobile Robots is a great example of its strengths.
This course is a relatively obscure topic, so Coursera’s partnerships with major universities enable Coursera to bring this course to the world much faster than Udacity’s in-house production model.
Often the cost for this flexibility is that Coursera courses are of uneven quality. But this course has super-high production values, which I think is a result of Georgia Tech’s focus on online education.
I mentioned previously that Toyota is coming into the autonomous vehicle game a little bit late, even if they do have more self-driving patents than any other company.
Eric Krotkov, Former DARPA Program Manager — Chief Operating Officer
Larry Jackel, Former Bell Labs Department Head and DARPA Program Manager — Machine Learning
James Kuffner, CMU Professor and former head of Google Robotics — Cloud Computing
John Leonard, Samuel C. Collins Professor of Mechanical and Ocean Engineering, MIT — Autonomous Driving
Hiroshi Okajima, Project General Manager, R&D Management Division, Toyota Motor Corporation — Executive Liaison Officer
Brian Storey, Professor of Mechanical Engineering, Olin College of Engineering — Accelerating Scientific Discovery
Russ Tedrake, Associate Professor in the Department of Electrical Engineering and Computer Science, MIT — Simulation and Control
In particular, I am somewhat familiar with Russ Tedrake, having taken his edX course on Underactuated Robotics. He is a fast-rising start in the robotics world, although thus far his specialty has been walking robots, not driving robots.
It looks like Toyota has a lot of leaders on the team. Now the question is whether they can stock up worker bees.