
Students in Udacity’s Self-Driving Car Engineer Nanodegree Program go above and beyond to build terrific implementations of vehicle detectors, lane line detectors, neural networks for end-to-end learning, and career advice.
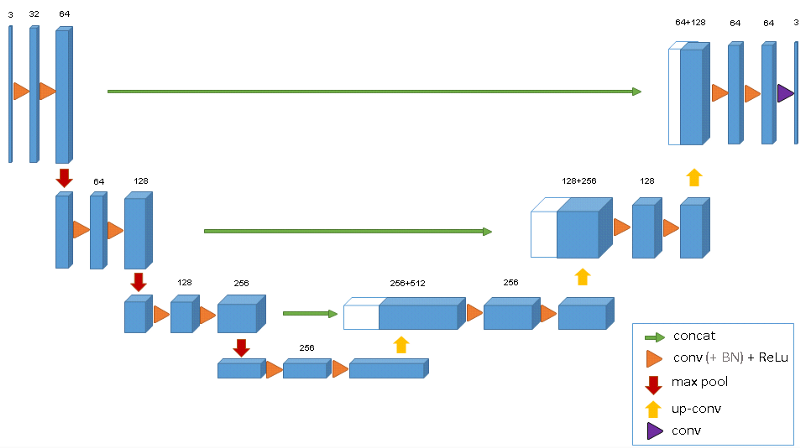
Small U-Net for vehicle detection
In the Vehicle Detection Project, students use standard computer vision methods to detect and localize vehicles in images taken from highway driving. Vivek went well beyond standard computer vision methods, and used U-Net, an encoder-decoder architecture that has proven effective for medical imaging. The results are astounding.
Another advantage of using a U-net is that it does not have any fully connected layers, therefore has no restriction on the size of the input image. This feature allows us to extract features from images of different sizes, which is an attractive attribute for applying deep learning to high fidelity biomedical imaging data. The ability of U-net to work with very little data and no specific requirement on input image size make it a strong candidate for image segmentation tasks.
My Lane Detection Project in the Self Driving Car Nanodegree by Udacity
Param provides a great walkthrough of his first project — Finding Lane Lines. He also includes a video that shows all of the intermediate steps necessary to find lane lines on the road. Then he applies his computer vision pipeline to a new set of videos!
This is the most important step, we use the Hough Transform to convert the pixel dots that were detected as edges into meaningful lines. It takes a bunch of parameters, including how straight should a line be to be considered a line and what should be the minimum length of the lines. It will also connect consecutive lines for us, is we specify the maximum gap that is allowed. This is a key parameter for us to be able to join a dashed lane into a single detected lane line.
Extrapolate lines with numpy.polyfit
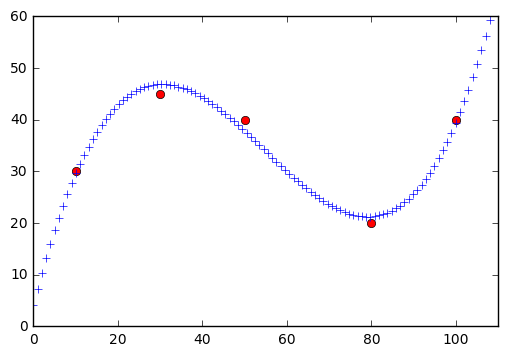
Leading up to the Finding Lane Lines project, we teach students about some important computer vision functions for extracting lines from images. These are tools like Hough transforms and Canny edge detection. However, we leave it to the students to actually identify which lines correspond to the lane lines. Most students find some points and extrapolate y=mx+b. Peteris went beyond this, though, and taught himself how to use the numpy.polyfit() function in order to identify the line equation automatically!
If return to the original question, how do we extrapolate the lines?
Since we got a straight line, we can simply plug in points that are outside of our data set.
An augmentation based deep neural network approach to learn human driving behavior

While training his end-to-end driving network for the Behavioral Cloning project, Vivek made us of extensive image augmentation. He flipped his images, resized them, added shadows, changed the brightness, and applied vertical and horizontal shifts. All of this allowed his model to generalize to an entirely new track that it had never seen before.
This was perhaps the weirdest project I did. This project challenged all the previous knowledge I had about deep learning. In general large epoch size and training with more data results in better performance, but in this case any time I got beyond 10 epochs, the car simply drove off the track. Although all the image augmentation and tweaks seem reasonable n0w, I did not think of them apriori.
But, Self-Driving Car Engineers don’t need to know C/C++, right?

Miguel’s practical post covers some of the different angles from which a self-driving car engineer might need to know C++, ROS, and other autonomous vehicle development tools. It’s a great read if you’re looking for a job in the industry!
Self-Driving Car Engineers use C/C++ to squeeze as much speed out of the machine as possible. Remember, all processing in autonomous vehicles is done in real-time and even sometimes in parallel architectures, so you will have to learn to code for the CPU but also the GPU. It is vital for you to deliver software that can process large amount of images (think about the common fps — 15, 30 or even 60) every second.
