
Here’s what I pulled out of “Fully Convolutional Networks for Semantic Segmentation”, by Long, Shelhamer, and Darrell, all at UC Berkeley. This is a pretty important research result for semantic segmentation, which we’ll be covering in the elective Advanced Deep Learning Module in the Udacity Self-Driving Car Program.
Segmentation
The ultimate goal of FCNs is to produce “semantic segmentation”. This is an output that is the same size as the original input image, and roughly resembles the original input image, but in which each pixel in the image is colored one of C colors, where C is the number of classes we are segmenting.
For a road image, this could be as simple as C=2 (“road”, or “not road”). Or C could capture a much richer class set.

Fully Convolutional
The basic idea behind a fully convolutional network is that it is “fully convolutional”, that is, all of its layers are convolutional layers.
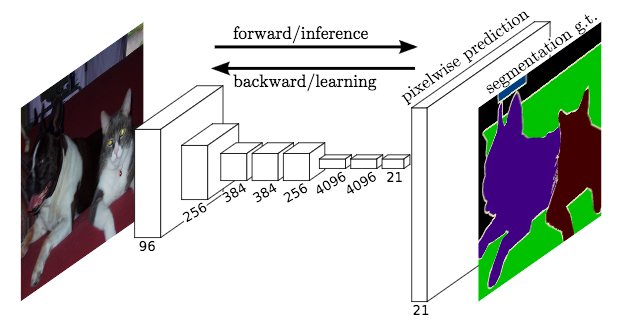
FCNs don’t have any of the fully-connected layers at the end, which are typically use for classification. Instead, FCNs use convolutional layers to classify each pixel in the image.
So the final output layer will be the same height and width as the input image, but the number of channels will be equal to the number of classes. If we’re classifying each pixel as one of fifteen different classes, then the final output layer will be height x width x 15 classes.
Using a softmax probability function, we can find the most likely class for each pixel.
Learnable Upsampling
A logistical hurdle to overcome in FCNs is that the intermediate layers typically get smaller and smaller (although often deeper), as striding and pooling reduce the height and width dimensions of the tensors.
FCNs use “deconvolutions”, or essentially backwards convolutions, to upsample the intermediate tensors so that they match the width and height of the original input image.
Justin Johnson has a pretty good visual explanation of deconvolutions (start at slide 46 here).
Because backward convolution layers are just convolutions, turned around, their weights are learnable, just like normal convolutional layers.
Smart.
Combining Layers
The authors had success converting canonical networks like AlexNet, VGG, and GoogLeNet into FCNs by replacing their final layers. But there was a consistent problem, which was that upsampling from the final convolutional tensor seemed to be inaccurate. Too much spatial information had been lost by all the downsampling in the network.
So they combined upsampling from that final intermediate tensor with upsampling from earlier tensors, to get more precise spatial information.

Pretty neat paper.
