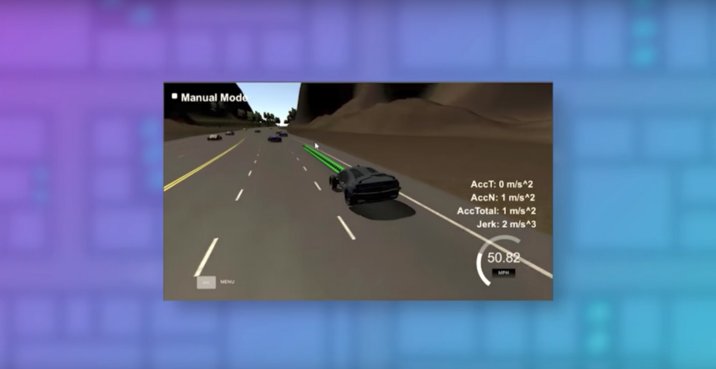
Bosch, the world’s largest automotive supplier (and also a Udacity Self-Driving Car partner) has published a neat Automated Mobility Academy that describes different levels of autonomous driving and key features at each level.
It’s basically a web series, free and targeted at the general public, that describes different parts of the autonomous vehicle ecosystem.
The stages are: Driver Assistance, Partially Automated Driving, Conditional and Highly Automated Driving, and Fully Automated Driving. These pages correspond roughly to Levels 2 through 5 of the SAE autonomy levels.
The David Silver — Udacity world tour continues next Tuesday, in Denver, Colorado! Come by the Autonomous Denver Meetup, graciously hosted at Uber’s Louisville, Colorado, office.
I’ll be presenting an overview of Carla, the Udacity Self-Driving Car that can drive itself from Mountain View to San Francisco.
Carla herself will not be present, sadly, but there will be lots of good videos and sensor data.
There will also an all-questions-welcome Q&A about Udacity, the Nanodegree Program, self-driving cars, and more. Please come!
This weekend I went to the DIY Robocar Meetup in Oakland, which is an awesome event if you’re excited about autonomous vehicles.
Lots of people gather in a warehouse of a day of hacking on miniature autonomous vehicles, and the day is capped off by a time trial.
I went to watch and to get my son out of the house so my wife could have the day to herself, but it was fun to meet lots of Udacity students who were participating.
Mr. Evan
All of them attested to how much they were learning by putting their skills to use on actual embedded hardware that had to run in realtime.
There are several of these Meetups springing up around the world, and there are even a number of kits you can buy to get up and running quickly. So if you are interested in the field, consider trying it out! And if there’s not a similar event near you, maybe you can start one 🙂
We recorded a video at Udacity recently in which I walked prospective students through the Nanodegree Program, including some new videos of Term 3 projects.
“…the e-commerce giant has long wanted to figure out the online groceries game. It started testing delivery concepts in August 2007, when it unveiled Amazon Fresh — delivering produce and pantry staples through its fulfillment centers. Yet even after a decade — eons in Silicon Valley time — it’s still trying. Turns out, the instant gratification business doesn’t quite work with fresh food.”
Forbes goes on to talk about the difficulties inherent to grocery retailing:
“A lot of the stuff you buy in a grocery store spoils easily, which means you have to get them home quickly — plus, someone has to be there to receive the goods. That can be tricky, given how Amazon likes to optimize delivery routes and bundle items to maximize efficiency.
This is precisely where self-driving cars come in. Optimizing delivery routes and bundling become drastically less important when the marginal cost of a delivery plummets by 50% or more.
AmazonFresh Pickup and Amazon Go are new spins on the grocery store, but neither of them seems particularly disruptive — more like a new spin on an old model. And the cognitive load of switching to a new commerce model might not be worth the relatively small benefit.
A deliver-groceries-to-me-right-now service, though, seems like it could make a lot of people think twice about piling into the car to go to Safeway.
Three Udacity students each took different approaches to vehicle detection and tracking — some using deep learning and others using standard computer vision. Here’s what they learned!
Ivan has a terrific writeup of how to use deep learning for vehicle detection. He builds a model based on Faster-RCNN, but smaller and faster.
“The main idea is that since there is a binary classification problem (vehicle/non-vehicle), a model could be constructed in such a way that it would have an input size of a small training sample (e.g., 64×64) and a single-feature convolutional layer of 1×1 at the top, which output could be used as a probability value for classification.”
Martijn uses a HOG and SVM approach to build a vehicle detection pipeline. He encountered some issues with noise and finds a creative solution.
“I was advised do try Hard Negative Mining to train my model more accurate, so I captured multiple images of the shadows / threes and added them to the non car image dataset. (to classify them among the non-car classes instead of the car classes)”
Priya uses a HOG and SVM approach to vehicle detection. By combining those with a threshold over time, she achieves great performance. She discusses some of the tradeoffs, however.
“Firstly, I am not sure this model would perform well when it is a heavy traffic situations when there are multiple vehicles. You need something with near perfect accuracy to avoid bumping into other cars or to ensure there are no crashes on a crossing. More importantly, the model was slow to run. It took 6–7 minutes to process 1 minute of video. I am not sure this model would work in a real life situation with cars and pedestrians on the road.”
One of the big open secrets in the autonomous vehicle world is Apple’s development of a car. Apple has refused to publicly acknowledge this, however, to the point that engineers widely believed to be working on the Apple car have just removed their LinkedIn profiles.
While maintaining a determined poker face about exactly what they’re building (is it a car? an automotive operating system?), Cook talked about the convergence of autonomy, electrification, and ride-sharing.
In a very short discussion, he seems to emphasize two points. One is the importance of electrification, which perhaps points to Apple building a physical product. The other is the application of autonomy beyond cars. Maybe Apple drones are next.
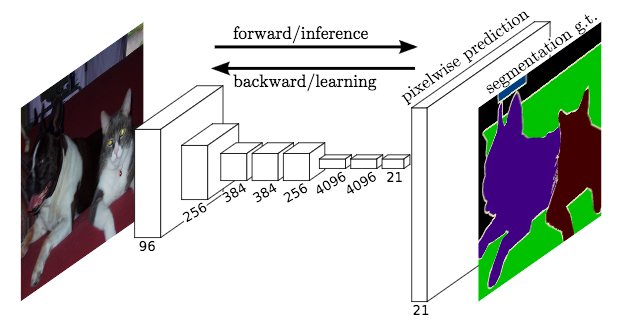
The ultimate goal of FCNs is to produce “semantic segmentation”. This is an output that is the same size as the original input image, and roughly resembles the original input image, but in which each pixel in the image is colored one of C colors, where C is the number of classes we are segmenting.
For a road image, this could be as simple as C=2 (“road”, or “not road”). Or C could capture a much richer class set.
An example of semantic segmentation from the KITTI dataset.
Fully Convolutional
The basic idea behind a fully convolutional network is that it is “fully convolutional”, that is, all of its layers are convolutional layers.
FCNs don’t have any of the fully-connected layers at the end, which are typically use for classification. Instead, FCNs use convolutional layers to classify each pixel in the image.
So the final output layer will be the same height and width as the input image, but the number of channels will be equal to the number of classes. If we’re classifying each pixel as one of fifteen different classes, then the final output layer will be height x width x 15 classes.
Using a softmax probability function, we can find the most likely class for each pixel.
Learnable Upsampling
A logistical hurdle to overcome in FCNs is that the intermediate layers typically get smaller and smaller (although often deeper), as striding and pooling reduce the height and width dimensions of the tensors.
FCNs use “deconvolutions”, or essentially backwards convolutions, to upsample the intermediate tensors so that they match the width and height of the original input image.
Justin Johnson has a pretty good visual explanation of deconvolutions (start at slide 46 here).
Because backward convolution layers are just convolutions, turned around, their weights are learnable, just like normal convolutional layers.
Smart.
Combining Layers
The authors had success converting canonical networks like AlexNet, VGG, and GoogLeNet into FCNs by replacing their final layers. But there was a consistent problem, which was that upsampling from the final convolutional tensor seemed to be inaccurate. Too much spatial information had been lost by all the downsampling in the network.
So they combined upsampling from that final intermediate tensor with upsampling from earlier tensors, to get more precise spatial information.
We covered everything from deep learning, to the SAE automation levels, to safety and security, to public policy. There were lots of great questions and it was lots of fun.
Juan and Antonio rigged up a lightweight video recording from a laptop webcam, and I think it came out surprisingly well. Feel free to watch below.