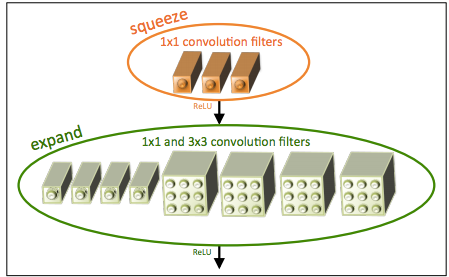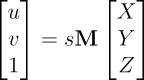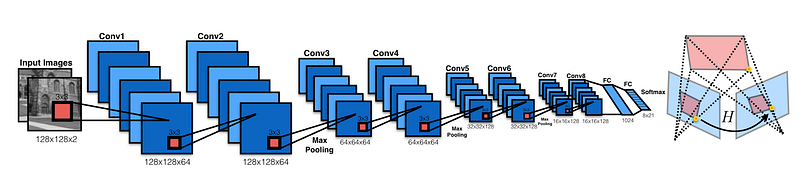
Udacity democratizes education by bringing world-class instruction to students around globe. Often, we’re humbled to see how students build on that education to create their own projects outside of the classroom.
Here are five amazing deep learning projects by students in the Udacity Self-Driving Car Engineer Nanodegree Program.
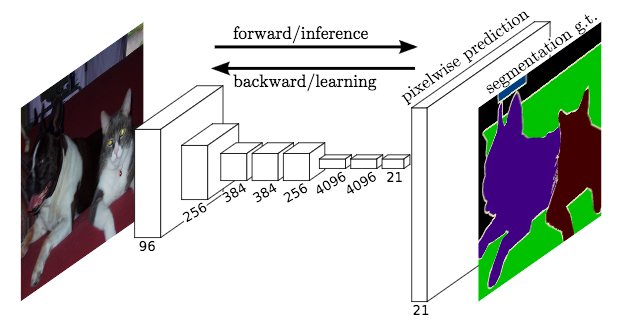
HomographyNet: Deep Image Homography Estimation
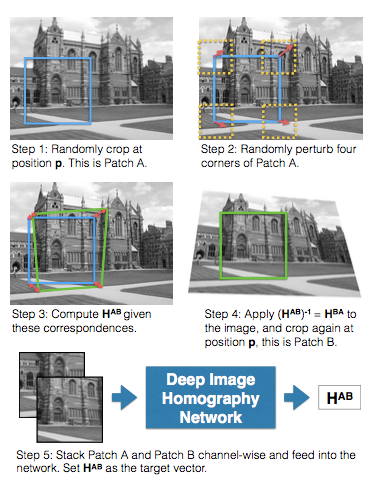
Mez starts off with a plain-English explanation of what isomorphism and homography are. Homography is basically the study of how one object can look different when viewed from different places. Think about how your image of a car changes when you take a step to the left and look at it again.
After the conceptual explanation, Mez dives into the mechanics of how to combine computer vision, image processing, and deep learning to train a VGG-style network to perform homography.
I imagine this could be a useful technique for visual localization, as it helps you stitch together different images into a larger map.
“HomographyNet is a VGG style CNN which produces the homography relating two images. The model doesn’t require a two stage process and all the parameters are trained in an end-to-end fashion!”
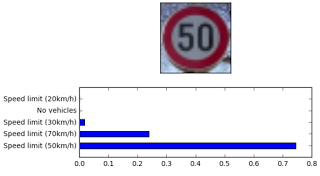
ConvNets Series. Image Processing: Tools of the Trade

Kirill uses the Traffic Sign Classifier Project from the Nanodegree Program as a jumping off point for discussing approaches to image pre-processing. He covers three approaches: visualization, scikit-learn, and data augmentation. Critical topics for any perception engineer!
“Convnets cannot be fed with “any” data at hand, neither they can be viewed as black boxes which extract useful features “automagically”. Bad to no preprocessing can make even a top-notch convolutional network fail to converge or provide a low score. Thus, image preprocessing and augmentation (if available) is highly recommended for all networks.”
Launch a GPU-backed Google Compute Engine instance and setup Tensorflow, Keras and Jupyter

We teach students in the Nanodegree Program how to use Amazon Web Services to launch a virtual server with a GPU, which accelerates training neural networks. There are alternatives, though, and Steve does a great job explaining how you would accomplish the same thing using Google Cloud Platform.
“Good news: if it’s your first time using Google Cloud you are also eligible for $300 in credits! In order to get this credit, click on the big blue button “Sign up for free trial” in the top bar.”
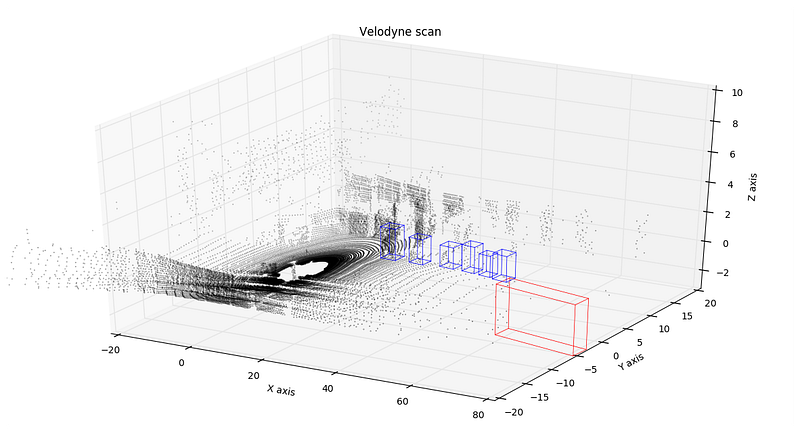
Yolo-like network for vehicle detection using KITTI dataset

Vivek has written terrific posts on a variety of neural network architectures. In this post, which is the first in a series, he prepares YOLO v2 to classify KITTI data. He goes over six pre-processing steps: learning bounding boxes, preprocessing the ground truth bounding boxes, preprocessing the ground truth labels, overfitting an initial network (a Vivek specialty), data augmentation, and transfer learning.
“ YOLOv2 has become my go-to algorithm because the authors correctly identified majority of short comings of YOLO model, and made specific changes in their model to address these issues. Futher YOLOv2 borrows several ideas from other network designs that makes it more powerful than other models like Single Shot Detection.”
DeepSchool.io

Sachin has built an 18 lesson curriculum for deep learning, hosted via GitHub, called DeepSchool.io. The lessons start with the math of deep learning, take students through building feedforward and convolutional networks, and finish with using LSTMs to classify #FakeNews! Yay, 21st century America.
Goals
Make Deep Learning easier (minimal code).
Minimise required mathematics.
Make it practical (runs on laptops).
Open Source Deep Learning Learning.