The Udacity Self-Driving Car Engineer Nanodegree Program requires students to complete a number of projects, and each project requires some experimentation from students to figure out a solution that works.
Here are five posts by Udacity students, outlining how they used experimentation to complete their projects.
Self-Driving Car Engineer Diary — 4
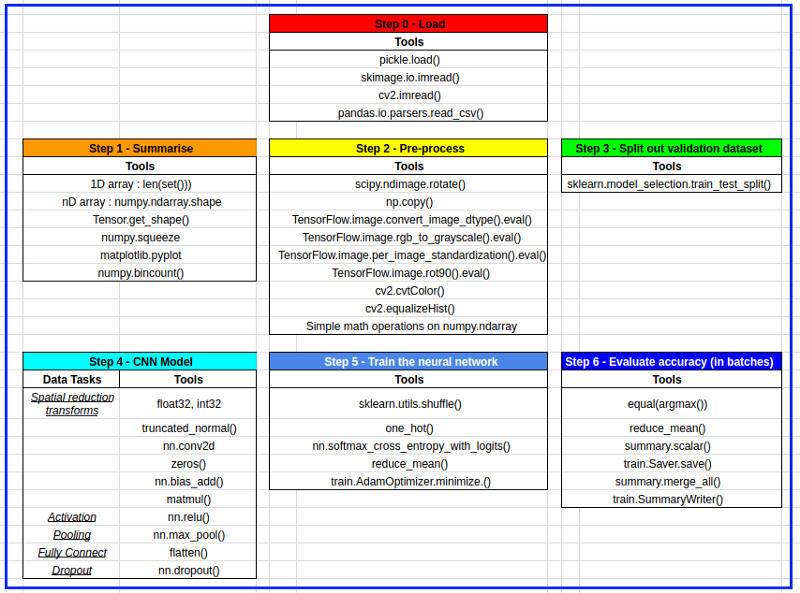
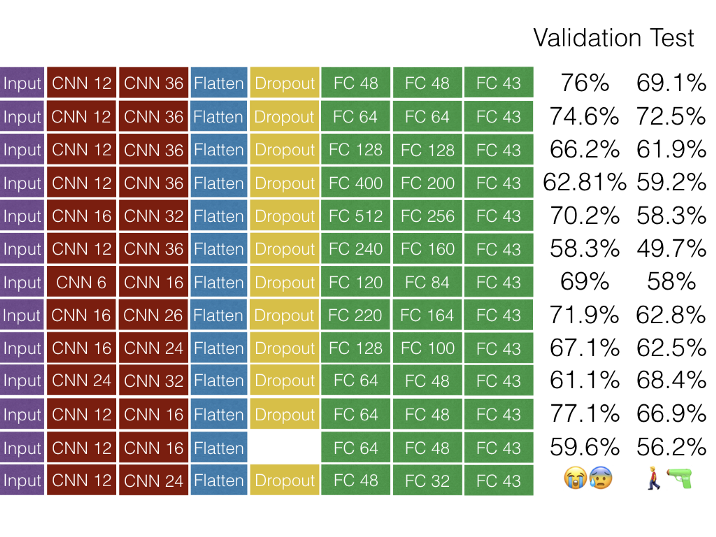
Andrew has lots of images in this blog post, including a spreadsheet of all the different functions he used in building his Traffic Sign Classifier with TensorFlow!
I got to explore TensorFlow and various libraries (see table below), different convolutional neural network models, pre-processing images, manipulating n-dimensional arrays and learning how to display results.
Intricacies of Traffic Sign Classification with TensorFlow
In this post, Param goes step-by-step through his iterative process of finding the right combination of pre-processing, augmentation, and network architecture for classifying traffic signs. 54 neural network architectures in all!
I went crazy by this point, nothing I would do would push me into the 90% range. I wanted to cry. A basic linearly connected model was giving me 85% and here I am using the latest hotness of convolution layers and not able to match.
I took a nap.
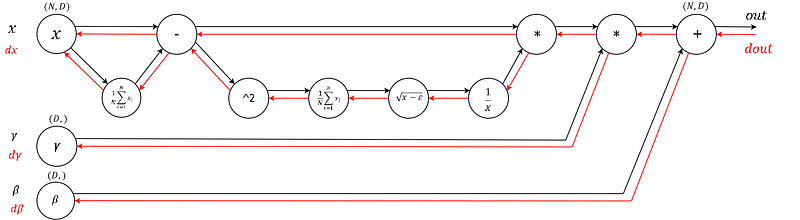
Backpropagation Explained
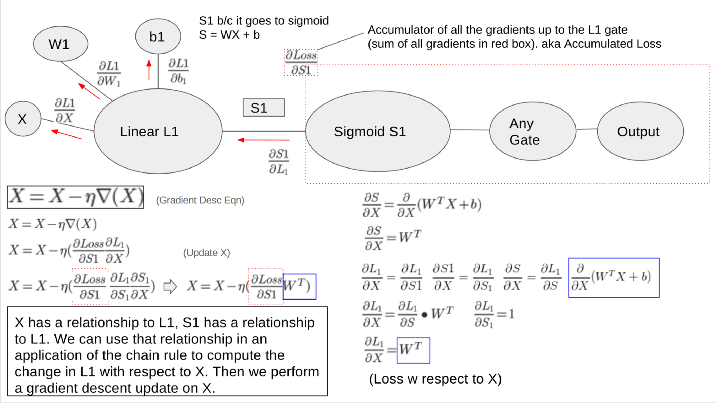
Backpropagation is the most difficult and mind-bending concept to understand about deep neural networks. After backpropagation, everything else is a piece of cake. In this concise post, Jonathan takes a crack and summarizing backpropagation in a few paragraphs.
When we are training a neural network we need to figure out how to alter a parameter to minimize the cost/loss. The first step is to find out what effect that parameter has on the loss. Then find the total loss up to that parameters point and perform the gradient descent update equation to that parameter.
Teaching a car to drive itself
Arnaldo presents a number of lessons he learned while designing an end-to-end network for driving in the Behavioral Cloning Project. In particular, he came to appreciate the power of GPUSs.
Using GPU is magic. Is like to give a Coke to someone in the desert. Or to buy a new car — the feeling of ‘how I was using that crap old one’. Or to find a shortcut in the route to the office: you’ll never use the long route again. Or to find a secret code in a game that give superpowers…
Robust Extrapolation of Lines in Video Using Probabilistic Hough Transform
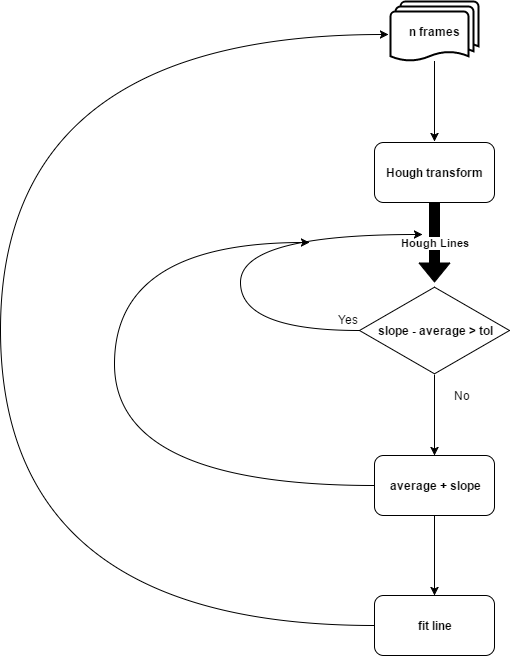
Esmat presents a well-organized outline of his Finding Lane Lines Porject and the computer vision pipeline that he used. In particular, he has a nice explanation of the Hough transform, which is a tricky concept!
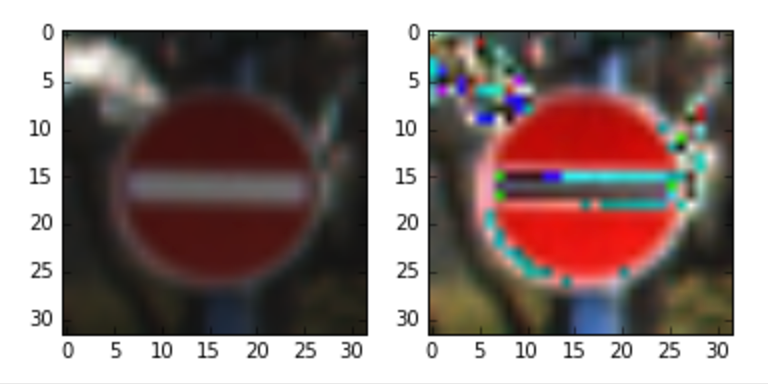
The probabilistic Hough line transform more efficient implementation of Hough transform. It gives as output the extremes of the detected lines (x0, y0, x1, y1). It is difficult to detect straight lines which are part of a curve because they are very very small. For detecting such lines it is important to properly set all the parameters of Hough transform. Two of most important parameters are: Hough votes and maximum distance between points which are to be joined to make a line. Both parameters are set at their minimum value.